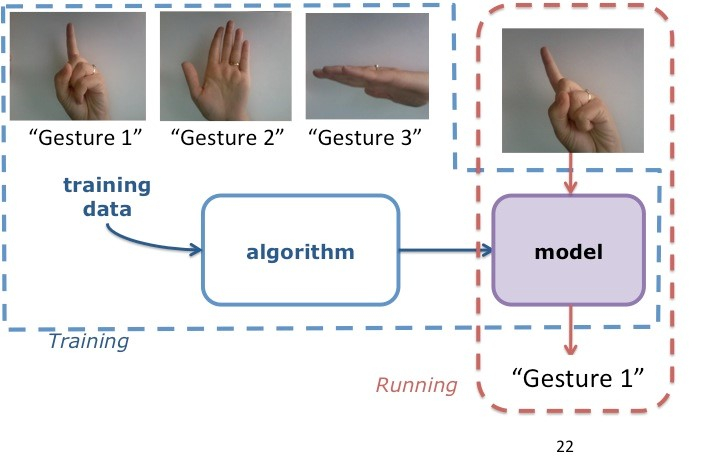
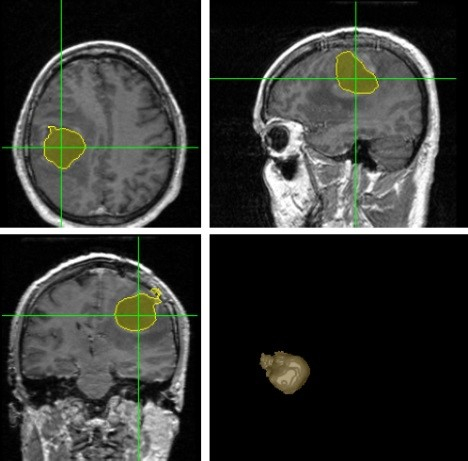
现代统计学近二十多年来的巨大发展使得对大数据的分析变成可能,其中对生物医疗数据的分析和应用更是万众瞩目。从制药疗效控制到癌症基因分析,大量与医疗相关的数据被利用作为前沿分析,来进行精确的量化分析。例如2002年自然杂志上刊登的由Laura van ‘t Veer博士等人研究的关于乳腺癌转移风险的预测。其使用的数据是基于70个人体中和乳腺癌相关的基因。通过基因检测出的数值,可以较为精确的预测病人乳腺癌转移的风险。基于该研究研制出的MammaPrint基因测试已被美国FDA(Food and Drug Administration) 通过验证,足见其数据分析的可靠性。